Optimización de Infraestructura Cloud y Alta Disponibilidad
Nota: Este caso de estudio documenta una intervención técnica crítica realizada para garantizar la estabilidad de una plataforma SaaS con alta demanda de usuarios.
Resumen del Proyecto
Durante un periodo de alta carga, la plataforma experimentó degradación en los tiempos de respuesta, llegando a bloqueos intermitentes. Como encargado de la infraestructura, lideré un proceso de diagnóstico profundo que abarcó desde el código frontend y backend hasta el análisis de recursos en el clúster y la base de datos.
El resultado fue una reestructuración de la capacidad de cómputo y una optimización de la capa de datos que eliminó los tiempos de inactividad y mejoró la experiencia del usuario final.
Objetivos
- Identificar y eliminar cuellos de botella en el flujo de peticiones entre el frontend y el backend.
- Garantizar la estabilidad del sistema mediante el escalamiento eficiente de recursos en la nube.
- Implementar monitoreo proactivo para prevenir futuros incidentes de saturación de datos.
Desafíos y Soluciones
- Diagnóstico Multicapa:
- Realicé una investigación integral utilizando logs de contenedores y métricas de base de datos, detectando una query de alta demanda que generaba bloqueos en cadena.
- Identifiqué que la arquitectura original no distribuía correctamente la carga durante procesos masivos de inicio de mes.
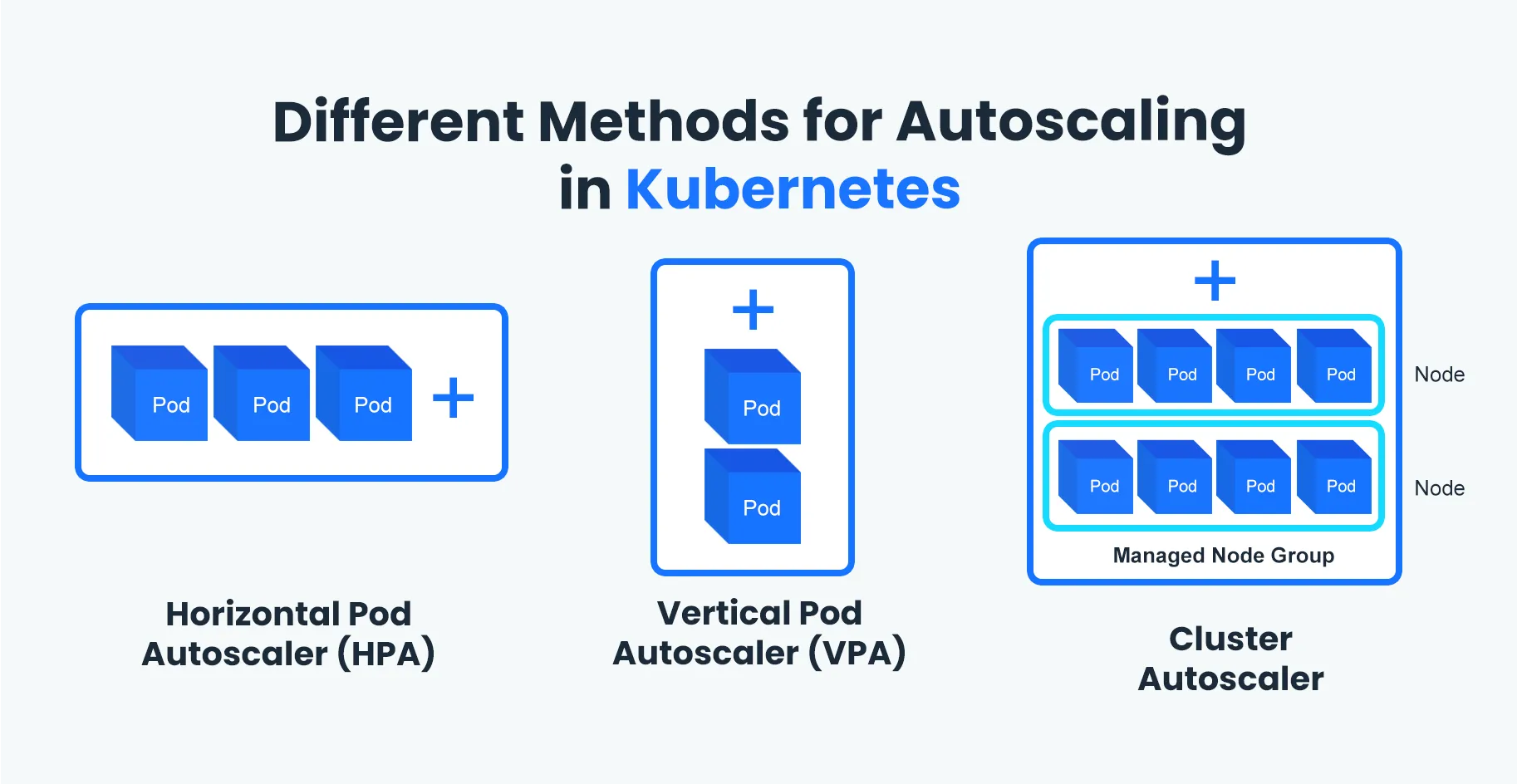
- Escalamiento de Infraestructura (Kubernetes):
- Implementé un escalamiento horizontal del backend, configurando réplicas (3 pods) para asegurar la alta disponibilidad.
- Ajusté el escalamiento vertical de los nodos en DigitalOcean para absorber picos de demanda sin degradar el rendimiento general.
- Optimización de Capa de Datos:
- Refactoricé la consulta SQL problemática, mejorando la estrategia de indexación y reduciendo el costo de ejecución en más de un 60%.
- Implementé limpiezas automáticas de datos redundantes o “basura” que saturaban los procesos de monitoreo.
- Monitoreo y Prevención:
- Establecí una ruta de actuación técnica (runbook) para incidentes, permitiendo al equipo responder con precisión ante anomalías en los despliegues.
Technology Stack
- Orquestación: Kubernetes (Pods, Deployments, ReplicaSets).
- Cloud Provider: DigitalOcean & AWS S3.
- Base de Datos: PostgreSQL (Optimización de Query Plan).
- Frontend/Backend: Vue.js y Node.js.
Resultado
La intervención no solo devolvió la estabilidad al sistema, sino que lo hizo más robusto frente a futuros crecimientos. La transición de un único despliegue a un sistema replicado garantizó que, ante el fallo de un nodo, el servicio continuara operando sin interrupciones. Esta cultura de “prevención de incendios” redujo significativamente los tickets de soporte relacionados con el rendimiento de la aplicación.